TABLE OF CONTENTS
- PYT-102
- Topic 1: Recursion & Dictionaries
- Topic 2: Python Modules & Errors Handling
- Topic 3: NumPy & Crio IDE
- - Deep Copy vs Shallow Copy
- - Introduction to Crio Jupyter IDE
- - List vs NumPy
- - Statistical Operations
- Statistical operations help uncover insights from data, such as averages, trends, and variation—critical for effective analysis.What is it?These are mathematical computations performed on datasets to understand distribution, variability, and relationships.Where is it used?In all phases of analytics—exploratory data analysis, trend identification, anomaly detection, and feature engineering. - NumPy Functions
- - Matrix Operations
- Topic 4: Pandas DataFrames Basics
- Topic 5: Pandas Selection
- Topic 6: Missing Data & Text Ops
- Topic 7: Ranking & Grouping
- Data Ranking and Filtering
- - Ranking DataRanking helps identify top or bottom performers within your dataset based on numerical values.What is it?The rank() function assigns a rank to each value, with the smallest value getting the lowest rank.Where is it used?In scenarios like top 10 revenue products, ranked scores, or sales leaderboards.How is it used?• df['Rank'] = df['Revenue'].rank(ascending=False)• Use method='dense' to avoid gaps in rank numbers
- Ways to Rank in Pandas:
- - Filtering with Conditions
- Counting and Aggregating Data
- - Counting Unique Values
- - Grouping Data
- – Handling Duplicates
- Topic 8: OOP in Python – Basics
- Object-Oriented Programming (OOP) in Python - I
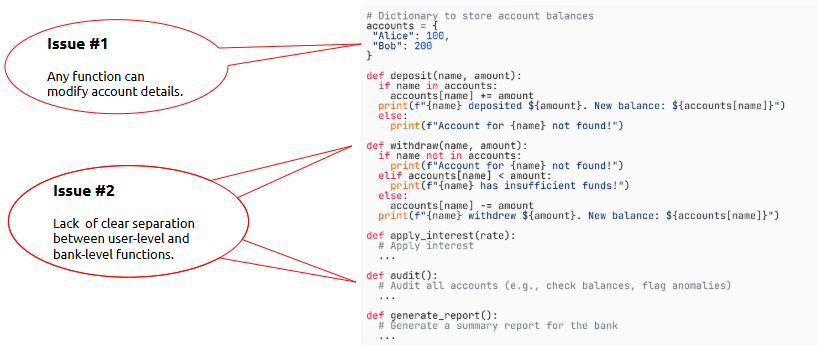
- Understanding the Need for OOP
- Basics of OOP
- - Classes and Objects’
- Classes and objects are the foundation of OOP.What is it?A class defines a blueprint; an object is an instance of that class.Where is it used?In structuring complex data logic such as defining Customer, Product, or AnalysisModel.How is it used?• Use class keyword to define• Use object = ClassName() to create an instance• Access attributes and methods with dot notation
- - self,__init__ Constructor Keyword
- Handling Functions Within Classes
- Topic 9: OOP in Python – Advanced
- Topic 10: Interview Readiness
PYT-102
Sprint summary
Getting Started
Topic 1: Recursion & Dictionaries
- Recursion
Recursion is when a function calls itself this technique is helpful for solving problems that can be broken down into similar sub-problems.
What is it?
A method where the solution to a problem depends on solving smaller instances of the same problem using self-calling functions.
Where is it used?
Used in tree/graph traversal, breaking down complex problems, computing factorials, Fibonacci series, and more.

How is it used?
• Define a base case to stop recursion
• Define a recursive case that calls the function again
• Example:
Below is the flow of above example:

--- Takeaways / best practices
• Always define a base case to avoid infinite loops
• Be mindful of the maximum recursion depth
• Recursive solutions can be elegant but may be less efficient than loops
• Use recursion when a problem fits naturally into divide-and-conquer format
- List Comprehensions
List comprehensions allow you to write cleaner, more concise loops that create new lists based on conditions or transformations.
What is it?
A compact way to create lists using a single line of code that includes a loop and an optional condition.

Where is it used?
Used for transforming lists, filtering data, and generating sequences efficiently.
How is it used?
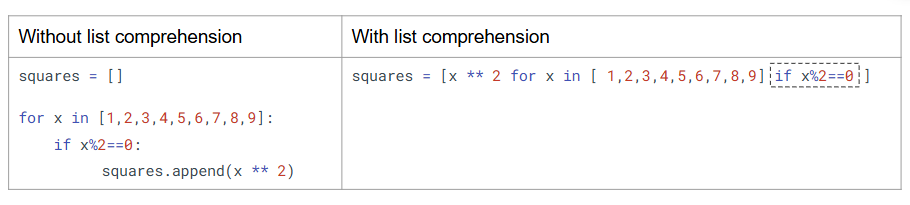
• Basic example:
Output: [1, 4, 9, 16]
• With condition:
Output: [2, 4]
--- Takeaways / best practices
• Use for cleaner and more readable transformations
• Avoid complex logic inside list comprehensions to maintain clarity
• They are faster than traditional for loops for list operations
• You can nest them, but readability can suffer—keep it simple
- Nested Dictionaries
Nested dictionaries allow storing complex, hierarchical data like JSON - perfect for structured records or grouped values.

What is it?
A dictionary within another dictionary, allowing multi-level key access.
Where is it used?
Used to model structured data like user profiles, configuration data, or nested JSON responses.
How is it used?
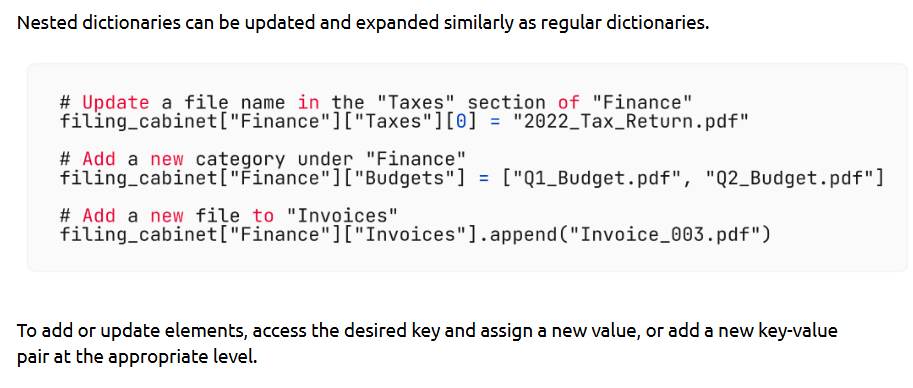
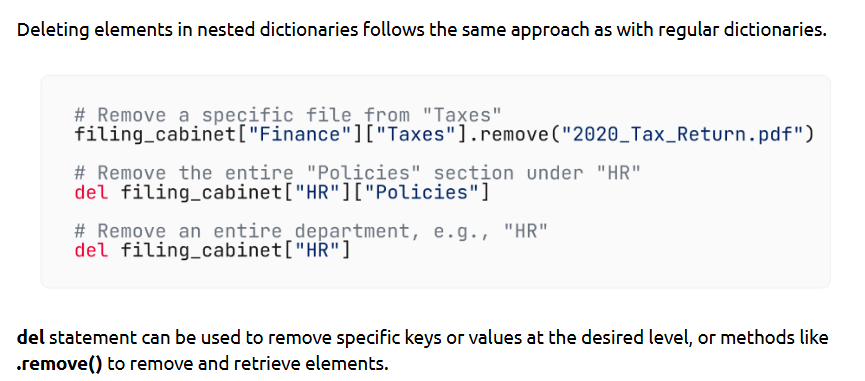
--- Takeaways / best practices
• Use when representing hierarchical or grouped data
• Always check if keys exist to avoid KeyError
• Combine with loops to process nested data effectively
• Useful when working with JSON APIs and structured dataset
- Dictionaries Vs JSON
Python dictionaries and JSON look similar but have key differences understanding both is crucial when working with APIs or saving data.
What is it?
Dictionaries are Python objects, while JSON is a text-based format used for data exchange.
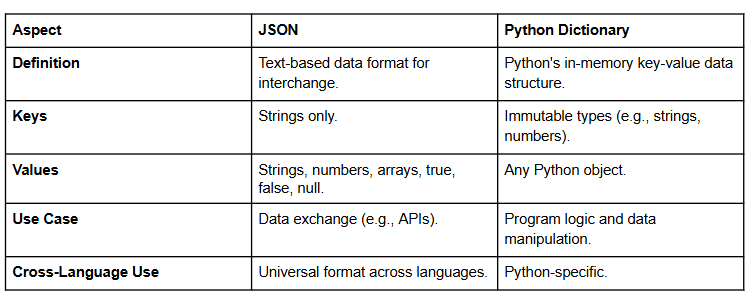
Where is it used?
Used in reading/writing API data, configuration files, and storing structured information.
How is it used?
• Python Dict to JSON:
• JSON to Python Dict:
--- Takeaways / best practices
• Use json.dumps() to serialize Python dicts into JSON
• Use json.loads() to deserialize JSON back into Python dicts
• JSON keys must be strings; Python dicts allow other types
• Ideal for saving, sharing, or receiving data across systems
Topic 2: Python Modules & Errors Handling
- Importing Python Modules
Modules allow you to reuse powerful, pre-built functionality-no need to reinvent the wheel!
Syntax:
What is it?
Modules are external or built-in Python files containing reusable code (functions, classes, constants).
Where is it used?
Used in all real-world analytics projects to access math, file handling, APIs, date/time, JSON, and more.
How is it used?
--- Takeaways / best practices
• Use built-in modules before writing custom functions
• Use aliases for long module names (as)
• Keep imports at the top of the script for readability
• Check documentation to explore all useful functions within a module
- math Module
The math module gives you access to advanced mathematical functions - perfect for calculations and data transformations.
Some methods and constants from the math module:
What is it?
A built-in module offering functions like square roots, logarithms, and constants (like pi and e).
Where is it used?
Used in data normalization, scientific calculations, rounding, and statistical processing.
How is it used?
• Import module:
• Example:
--- Takeaways / best practices
• Use math for precise mathematical operations
• Different from Python’s built-in round()
• math works only with numbers—avoid passing strings
• Great for preprocessing numeric features or formulas
- datetime Module
Working with dates and times? The datetime module is your go-to for parsing, formatting, and comparing date values.
What is it?
A module for manipulating dates and times as objects.
Where is it used?
Used in time-series analysis, parsing timestamps, filtering data by date, or calculating date differences.
How is it used?

--- Takeaways / best practices
• Use correct format codes for parsing (e.g., %Y, %m, %d)
• Combine with Pandas for time-indexed data
• Always standardize time zones if comparing timestamps
• Helpful in filtering, grouping, and visualizing temporal data
- json Module
JSON is everywhere from APIs to config files and the json module helps you work with it like a Python pro.
What is it?
A module that allows you to convert between JSON (string) and Python dictionaries.
Where is it used?
Used in web APIs, storing structured data, exporting results, and working with external services.
How is it used?

--- Takeaways / best practices
• Use dumps() to save Python data to JSON
• Use loads() to parse incoming JSON
• JSON only supports string keys and basic types
• Essential when reading API responses or saving data to disk
- Regex and re Module
Regular expressions help you search, clean, and extract patterns from messy text—critical for preprocessing data.
What is it?
Regex (regular expressions) is a way to define patterns for string matching, supported via the re module.
Regular Expression - Metacharacters:
Regular Expression - Special Sequences:
Regular Expression - Sets:
Where is it used?
Used in log analysis, cleaning unstructured data, validating formats (like emails), and text parsing.
How is it used?


--- Takeaways / best practices
• Use r"" raw string format for regex patterns
• Regex is powerful but can be complex—test your pattern
• Use for extracting IDs, tags, numbers, or structured parts of text
• Mastering regex boosts your ability to clean real-world datasets
- Exception Handing
Exception handling lets your code gracefully recover from errors like missing files or bad input, without crashing.
What is it?
A system to catch and respond to errors using try, except, and optionally finally.

Where is it used?
Used in file handling, user input, data conversions, and API calls—anywhere errors may occur.
Common Types of Errors to be handled:
How is it used?
• Example:
Output:
• Use except to handle specific error types (e.g., KeyError, IndexError)
--- Takeaways / best practices
• Always handle predictable errors (like user input or file issues)
• Avoid generic except: unless truly needed
• finally runs whether an error occurs or not—use for cleanup
• Use exception handling to make robust, user-friendly code
Topic 3: NumPy & Crio IDE
- Deep Copy vs Shallow Copy
Understanding how data is copied in Python is crucial when working with lists or complex data structures. A wrong copy type can lead to unexpected changes in your dataset.
What is it?
A shallow copy creates a new object but copies references to nested objects. A deep copy creates a new object and also copies all nested objects recursively.
Where is it used?
In data analytics, especially when manipulating large lists or structures like tables, dictionaries, or NumPy arrays where you don't want changes in one to affect the other.
How is it used?
• Use copy.copy() for a shallow copy
• Use copy.deepcopy() to duplicate both outer and inner elements
• NumPy uses .copy() for deep-like copying of arrays
Shallow Copy:

Deep Copy:
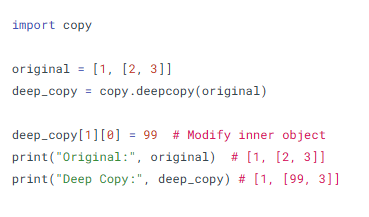
--- Takeaways / best practices
• Use deep copy when copying nested data that must remain unchanged
• Be cautious: shallow copy shares references and may cause data to change unexpectedly
- Introduction to Crio Jupyter IDE
Crio's Jupyter IDE is a browser-based coding environment that helps you test and learn Python interactively using notebooks.
What is it?
It’s a lightweight and beginner-friendly Python coding interface, perfect for writing and executing blocks of code and seeing real-time results.
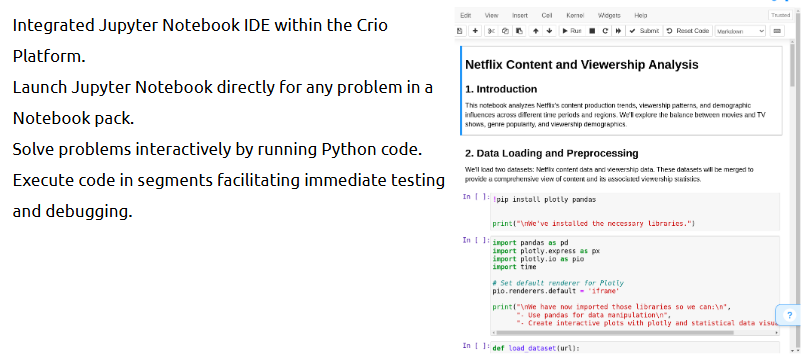
Where is it used?
During Python sprints, exercises, and assignments in Crio’s learning platform—especially for learning Python for data tasks.
How is it used?
• Open your course notebook from the dashboard
• Write Python code in cells and run them individually
• Use Shift + Enter to execute a cell
• View outputs and errors right below each cell
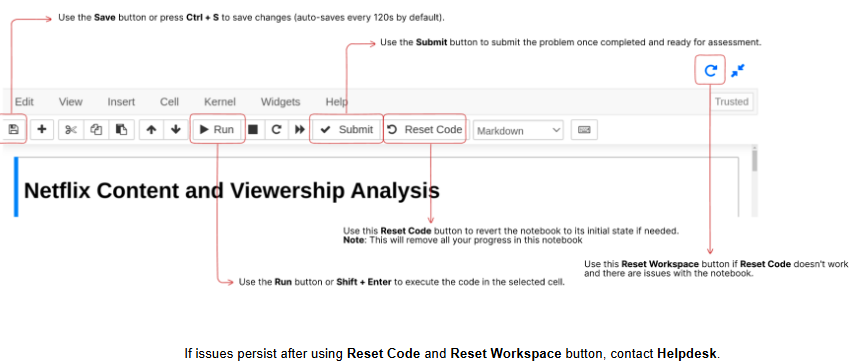
--- Takeaways / best practices
• Ideal for experimenting with data line-by-line
• Helps organize code in a readable, testable format
• Use comments (#) and markdown cells to document code and logic
- List vs NumPy
Python lists are versatile, but NumPy arrays are powerful tools specifically designed for efficient numerical operations.
What is it?
A list is a flexible Python container. A NumPy array is a performance-optimized structure for large-scale numerical computations.
Where is it used?
Lists are suitable for general scripting; NumPy arrays are used for high-performance math, matrix operations, and data preprocessing.
How is it used?
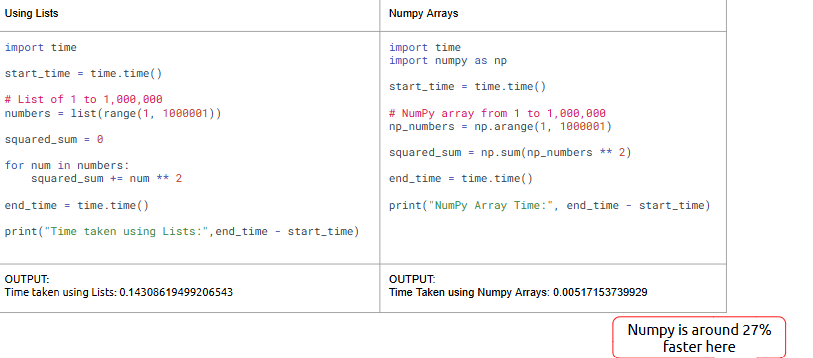
--- Takeaways / best practices
• NumPy arrays support fast, element-wise operations
• Prefer NumPy for large datasets and math-heavy processes
• Lists can't perform vectorized calculations efficiently
- Statistical Operations
Statistical operations help uncover insights from data, such as averages, trends, and variation—critical for effective analysis.
What is it?
These are mathematical computations performed on datasets to understand distribution, variability, and relationships.
Where is it used?
In all phases of analytics—exploratory data analysis, trend identification, anomaly detection, and feature engineering.
- NumPy Functions

How is it used?
- Matrix Operations

How is it used?
--- Takeaways / best practices
• Use NumPy for fast and scalable numerical analysis
• Master functions like mean, median, std, dot for common tasks
• Ensure shape compatibility when doing matrix operations
Topic 4: Pandas DataFrames Basics
- Pandas DataFrames
DataFrames are the core data structure in Pandas, used to handle tabular data — like an Excel sheet in Python.
What is it?
A 2D, labeled data structure with rows and columns, great for analyzing and transforming data.
Where is it used?
Used extensively in data cleaning, exploration, feature engineering, and transformation.
How is it used?
• Create with pd.DataFrame() from a dictionary, list of lists, or CSV
• Use .head() [View initial rows] and .info() to inspect
• Modify, filter, or aggregate using DataFrame methods

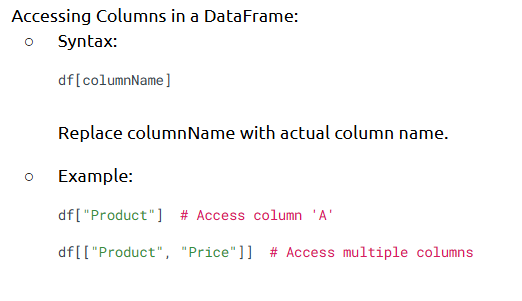

- Pandas Series
A Series is a one-dimensional array with labels (like a single column from a DataFrame).
What is it?
A labeled, one-dimensional array — similar to a column in Excel.
Where is it used?
For storing and analyzing individual columns or lists of values.
How is it used?
• Create with pd.Series()
• Access values using index or slicing
• Perform element-wise operations

Code:
- Reading CSV and Excel Data
To analyze real-world data, you need to load it from external files.
What is it?
Pandas allows you to read .csv or .xlsx files into a DataFrame.
Where is it used?
In almost every data project — CSV files are the most common data source.
How is it used?
• Use pd.read_csv('filename.csv') for CSV
• Use pd.read_excel('file.xlsx') for Excel
• Optional arguments: delimiter, header, sheet name, etc.
Code:

- Creating Columns
Add new columns to enhance or transform your dataset.
What is it?
You can create new columns using existing ones or assign fixed values.
Where is it used?
To add calculated fields or prepare data for modeling.
How is it used?
• Assign a new column directly using df['new_column'] = ...
• Use math or string operations on existing columns
Code:
- Data Preview
You always need to check your data before analysis.
What is it?
Functions like .head(), .tail(), .sample() give quick snapshots.
Where is it used?
During initial data loading and before applying transformations.
How is it used?
• .head(n) → first n rows
• .tail(n) → last n rows
• .sample(n) → random sample of n rows
Code:
- Handling Unique Separators in Data
Some CSV files use ; or | instead of commas — Pandas lets you handle that.
What is it?
You can define custom separators using the sep argument in read_csv.
Where is it used?
While importing data files that don’t follow the standard CSV format.
How is it used?
• Use pd.read_csv('file.txt', sep='|')
• Works for .csv, .txt, .dat files
Code:
- Parsing Dates Data
Dates often come as strings; parsing them into date objects is crucial for time-based analysis.
What is it?
Converting string-formatted dates into datetime objects using Pandas.
Where is it used?
In time series analysis, trend plotting, and date filtering.
How is it used?
• Use parse_dates=['column_name'] while reading
• Use pd.to_datetime() to convert later
Code:
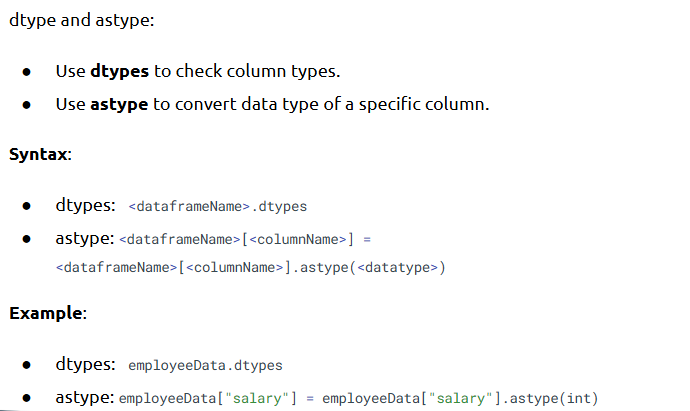
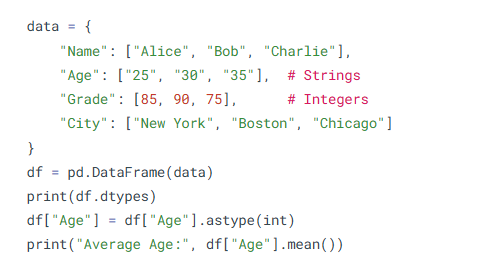
- Understanding Shape and Datatypes of DataFrames
Know your data’s structure and types before diving into analysis.
What is it?
.shape gives (rows, columns) and .dtypes shows data types per column.
Where is it used?
Early in data analysis to decide what cleaning and transformations are needed.
How is it used?
• df.shape → Get dimensions
• df.dtypes → Understand each column’s type
• df.info() → Summary including nulls and types
Topic 5: Pandas Selection
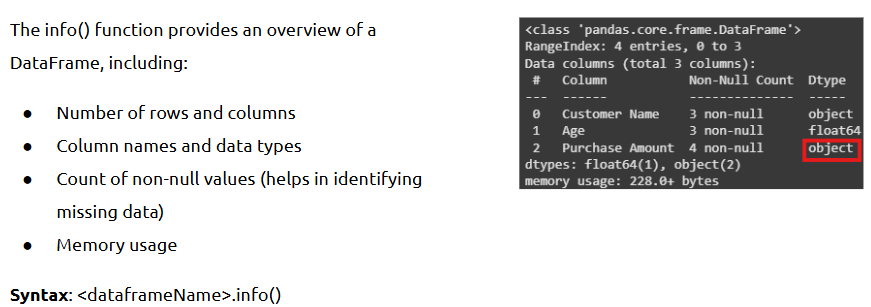
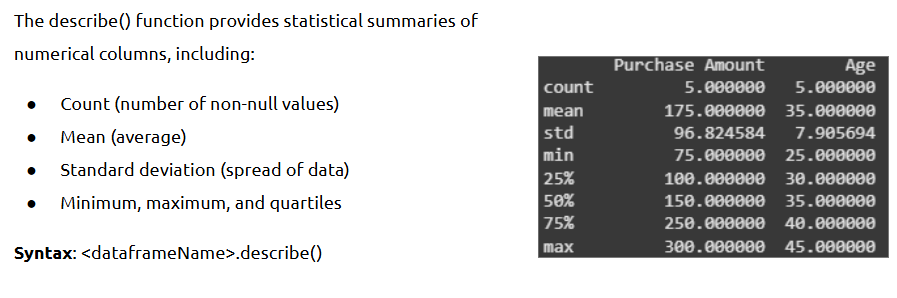
- Exploring Data using info() and describe()
Before any analysis, it's critical to understand the structure and summary statistics of your dataset.
What is it?
info() gives a concise summary of the DataFrame; describe() provides descriptive statistics for numerical columns.
Where is it used?
During the initial exploration phase to assess data types, null values, and basic distribution.
How is it used?
• df.info() → View column names, non-null counts, and data types
• df.describe() → Get count, mean, std, min, max, and percentiles
- Selecting Data using iloc and loc
Selecting specific rows and columns is essential to focus your analysis.
What is it?
iloc accesses data by index positions, while loc accesses data by labels or conditions.
Where is it used?
In data cleaning, filtering, sampling, or when isolating specific observations.
How is it used?

- Data Transformations using apply()
Transformations help you modify or derive new values from existing columns.
What is it?
apply() lets you apply a function to rows or columns of a DataFrame or Series.
Where is it used?
For row-wise or column-wise transformations, feature engineering, and formatting.
How is it used?
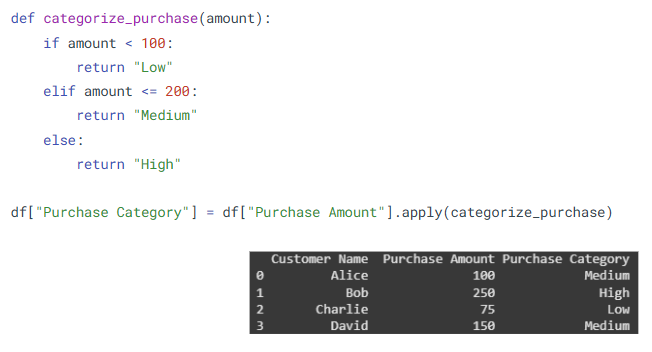
- Dropping Unnecessary Columns
Clean data is critical. Often, we need to remove irrelevant columns to streamline our dataset.
What is it?
Dropping columns removes unnecessary information that may clutter analysis or slow down processing.
Where is it used?
In data cleaning and optimization phases.
How is it used?
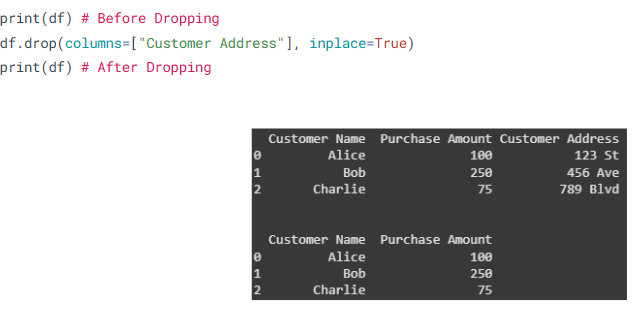
- Sorting DataFrames
Sorting helps you organize data to see trends, ranks, or find top/bottom performers.
What is it?
Use sort_values() to sort rows based on one or more columns.
Where is it used?
In reporting, ranking, or prioritization tasks.
How is it used?
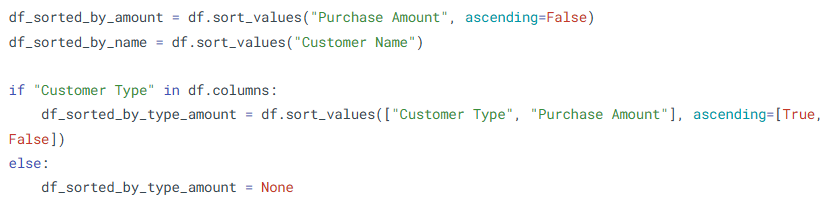
Topic 6: Missing Data & Text Ops
- Detect Missing Values with isnull()
Missing values are common in real-world data and need to be identified clearly before analysis or modeling.
What is it?
isnull() identifies NaN (Not a Number) or null entries in a DataFrame or Series.
Where is it used?
During data cleaning, especially before imputing or removing invalid data.
How is it used?
• df.isnull() → Returns a DataFrame with True/False
• df.isnull().sum() → Counts missing values per column
• Use any() to check if any column has nulls
Code:
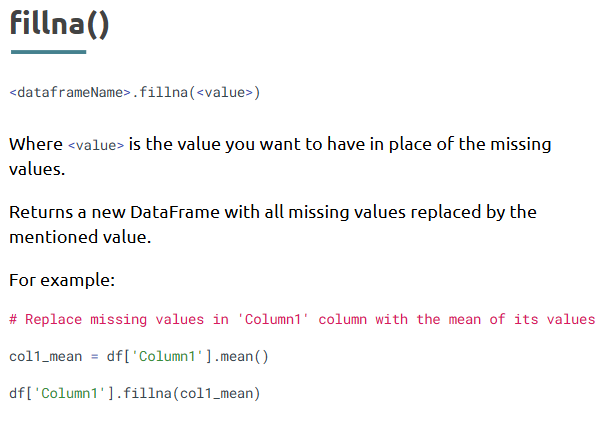
- Handling Missing Values with dropna() and fillna()
Once missing values are found, the next step is deciding whether to remove or fill them.
What is it?
dropna() removes rows with missing data, while fillna() replaces them with a specific value or method.
Where is it used?
In data cleaning and preprocessing pipelines to prepare data for analysis or ML models.
How is it used?
• df.dropna() → Drops rows with any null
• df.fillna(0) → Replaces nulls with 0
• df.fillna(df.mean()) → Replaces with column mean (numeric only)
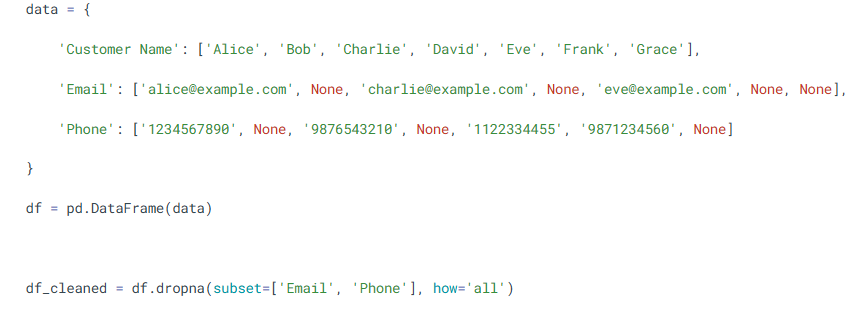
- Search for text in DataFrames using contains()
Text-based filtering is essential when working with categorical or free-text data.
What is it?
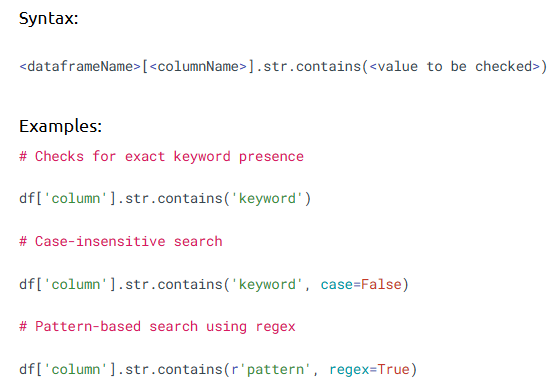
contains() checks whether a string exists in a column’s values using pattern matching.
Where is it used?
In filtering rows by text keywords, such as finding all entries with "error" or a particular city name.
How is it used?
• df['Column'].str.contains('text')
• Combine with .loc[] to filter rows
• Use na=False to avoid NaN-related errors
Code:
- Replacing Values with replace()
Sometimes you need to update incorrect labels, fix typos, or standardize data.
What is it?
replace() allows value-level substitutions in Series or DataFrames.
Where is it used?
In data cleaning to fix inconsistent values, rename categories, or anonymize data.
How is it used?
• df['Column'].replace('Old', 'New')
• Replace multiple values: df.replace(['Yes', 'No'], [1, 0])
• Can be applied on entire DataFrame
Code:

Topic 7: Ranking & Grouping
Data Ranking and Filtering
- Ranking Data
Ranking helps identify top or bottom performers within your dataset based on numerical values.
What is it?
The rank() function assigns a rank to each value, with the smallest value getting the lowest rank.
Where is it used?
In scenarios like top 10 revenue products, ranked scores, or sales leaderboards.
How is it used?
• df['Rank'] = df['Revenue'].rank(ascending=False)
• Use method='dense' to avoid gaps in rank numbers
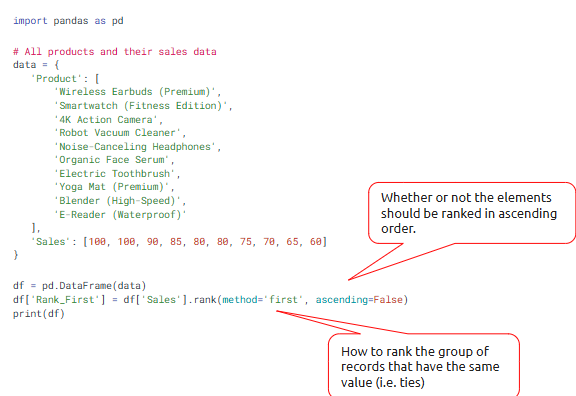
Ways to Rank in Pandas:
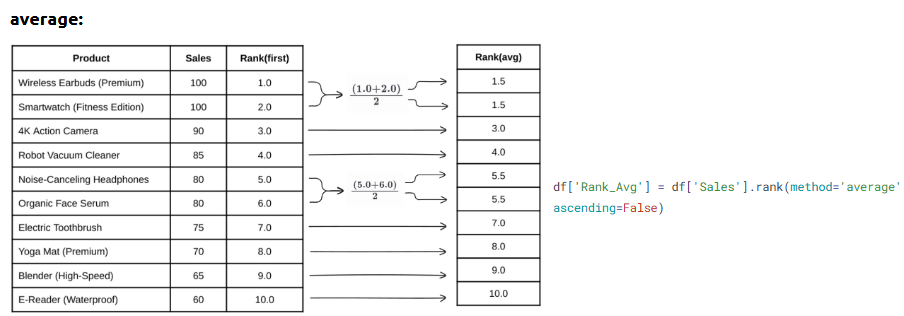
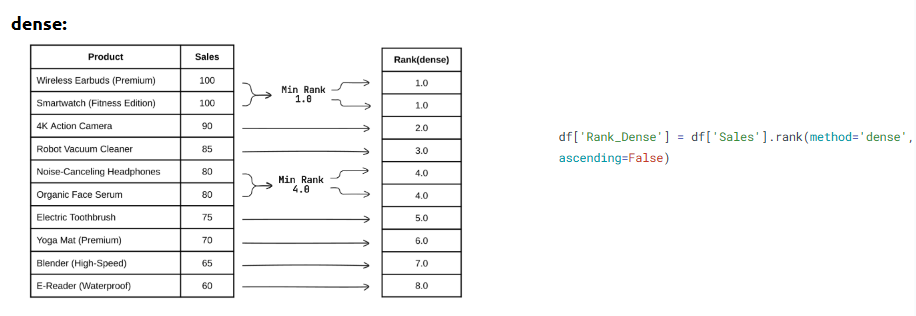
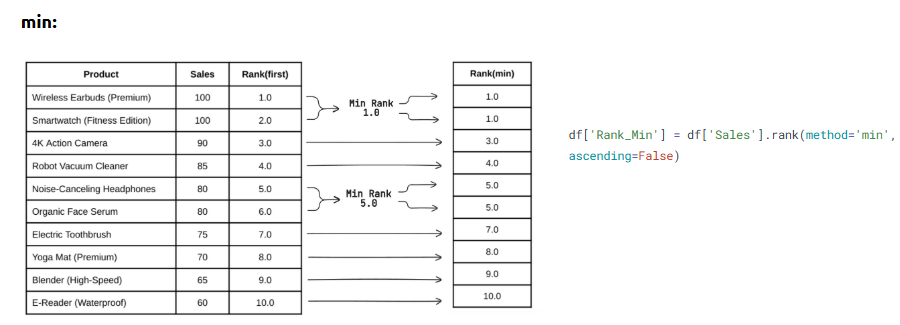
Code:
- Filtering with Conditions
Filtering data relies on logical comparisons like >, <, ==, and combining them with & or |.
What is it?
Logical operators are used to create boolean masks for filtering rows.
Where is it used?
In conditional analysis, such as filtering high-value transactions or invalid entries.
How is it used?
• df[df['Revenue'] > 1000]
• Combine multiple: df[(df['Revenue'] > 1000) & (df['Region'] == 'East')]
Ways to Filter:


Code:
Counting and Aggregating Data
- Counting Unique Values
Counting distinct entries helps summarize categorical data effectively.
What is it?
nunique() and value_counts() count distinct values and their frequencies.

Where is it used?
For category distribution, label frequency, or data health checks.
How is it used?
• df['Category'].nunique() → Count unique
• df['Category'].value_counts() → Frequency of each
Code:
- Grouping Data
Grouping allows you to summarize and compare metrics across categories.
What is it?
groupby() is used to split data into groups and perform aggregations like sum(), mean().
Where is it used?
In summarizing trends per region, product, category, etc.
How is it used?
• df.groupby('Category')['Revenue'].sum()
• Combine with multiple aggregations using .agg()
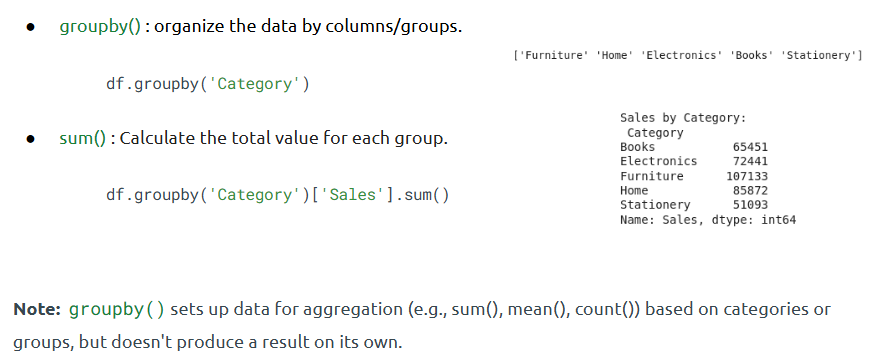
– Handling Duplicates
Duplicate rows can mislead analysis and inflate counts or totals.
What is it?
drop_duplicates() removes duplicate rows based on selected columns.
Where is it used?
When cleaning raw data before grouping, joining, or aggregating.
How is it used?
• df.drop_duplicates()
• df.duplicated() → Flags duplicates with True/False
Code:
Topic 8: OOP in Python – Basics
Object-Oriented Programming (OOP) in Python - I
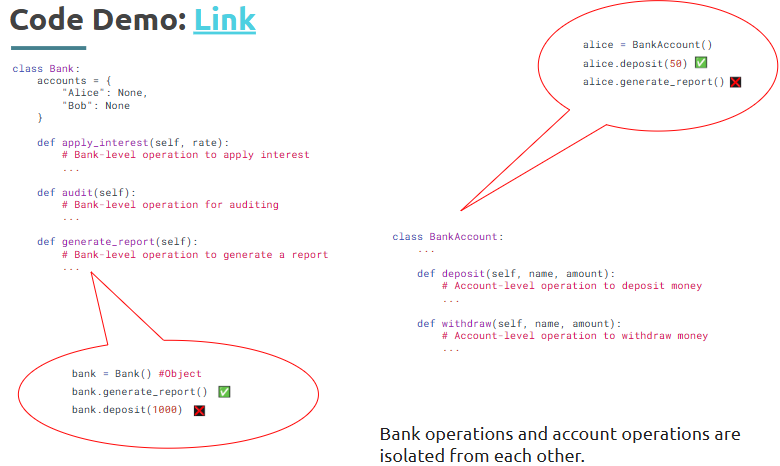
Object-Oriented Programming (OOP) is a programming approach that helps organize code logically and reuse components efficiently—which becomes especially useful as your analytics projects grow.
What is it?
A paradigm that uses classes and objects to structure programs by grouping related data and functions.
Where is it used?
In large-scale data analytics tools, automation scripts, dashboard frameworks, simulation models, and more—whenever code organization, scalability, and reusability matter.
How is it used?
• Define classes to model real-world entities like Dataset, Chart, or UserInput
• Instantiate objects from these classes to work with data
• Encapsulate methods (functions) to define object-specific behavior
• Use inheritance to extend functionality from existing classes
• Leverage constructors like __init__ to initialize object attributes
Takeaways / best practices
• OOP is ideal for building modular, reusable, and maintainable code structures
• Helps model real-world systems intuitively
• Improves collaboration by making code more organized and scalable
Understanding the Need for OOP
As projects grow in size and complexity, we need better structure than just functions and variables.
What is it?
Object-Oriented Programming (OOP) is a paradigm that organizes code using objects and classes to model real-world entities.
Where is it used?
In building scalable, reusable, and maintainable code for data pipelines, dashboards, and modular analysis tools.
How is it used?
• Define templates (classes) that represent entities (e.g., DataPoint, User, Report)
• Create objects (instances) to store and manipulate data
• Attach functions (methods) to these objects
Takeaways / best practices
• Use OOP to organize related data and behavior
• Promotes code reusability through inheritance
• Useful for large, collaborative data projects
Basics of OOP
- Classes and Objects’
Classes and objects are the foundation of OOP.
What is it?
A class defines a blueprint; an object is an instance of that class.
Where is it used?
In structuring complex data logic such as defining Customer, Product, or AnalysisModel.
How is it used?
• Use class keyword to define
• Use object = ClassName() to create an instance
• Access attributes and methods with dot notation

Example:

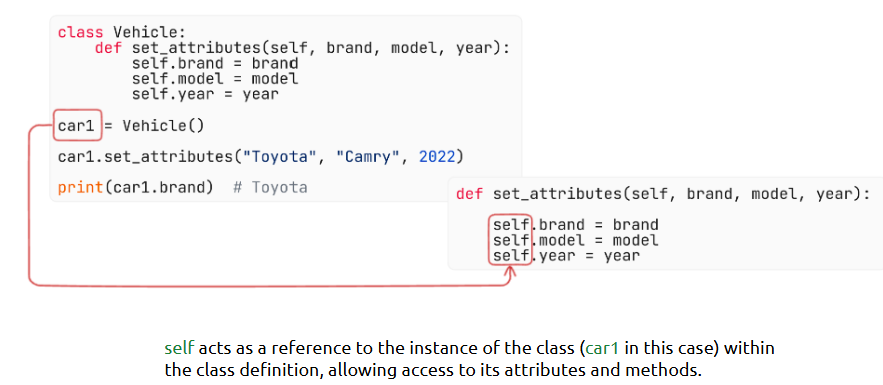
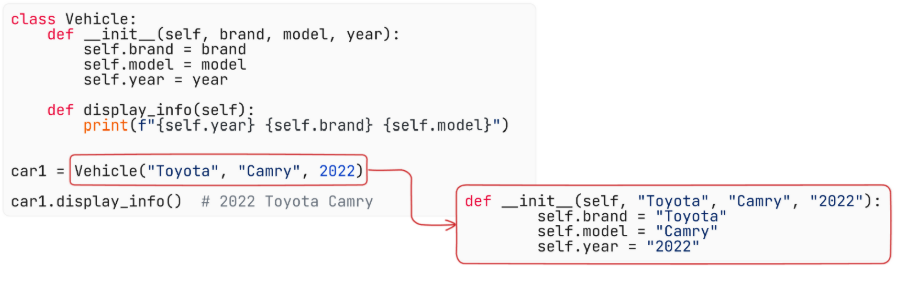
- self,__init__ Constructor Keyword
These are the tools that bring life to objects and enable inheritance.
What is it?
__init__ is the constructor that initializes object properties. self refers to the instance. super() lets child classes inherit parent behavior.
Where is it used?
In setting up object properties and extending parent classes in larger analytics applications.
How is it used?
• Define __init__() for initialization
• Always use self to refer to instance variables
self:

__init__:
Handling Functions Within Classes
Functions inside classes are called methods, and they define the behaviors of the object.
What is it?
Class functions that operate on data within an object and often reference self.
Where is it used?
In encapsulating logic specific to the object, like .calculate_profit() or .clean_data().
How is it used?
• Define functions inside class using def
• Use self to access instance variables
• Call methods using object.method()


Solution:
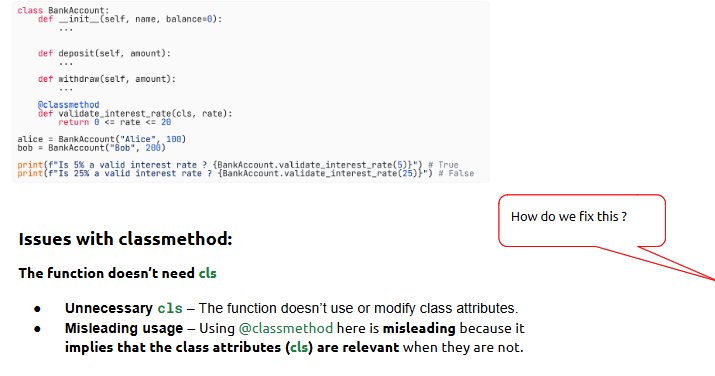

Topic 9: OOP in Python – Advanced
Object-Oriented Programming (OOP) in Python - II
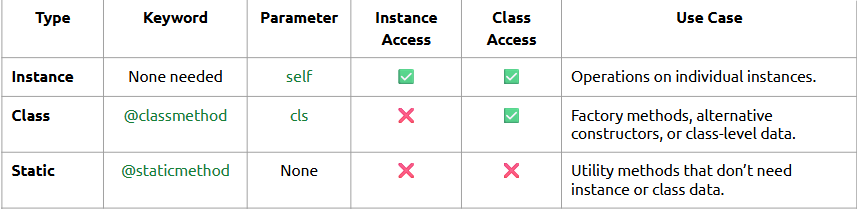
This session focuses on taking your object-oriented design to the next level making your classes more powerful and flexible using special methods and applying the core principles of OOP.
What is it?
OOP-II goes beyond the basics of classes and objects and introduces customization using dunder (double underscore) methods and the four key principles that guide modular programming.
Where is it used?
In scalable analytics frameworks, model pipelines, simulations, and custom data types or visualizations.
How is it used?
• Use __str__() and __len__() to customize object behavior
• Apply encapsulation to protect data
• Use inheritance to reuse code
• Enable polymorphism for dynamic behavior
• Leverage abstraction to simplify complexity
Special Methods
- Understanding __main__
What is it?
__main__ is the name given to the top-level script environment. Code inside if __name__ == "__main__" runs only when the script is run directly.
Where is it used?
In structuring Python scripts—especially in modular code, utilities, and testing.
How is it used?
• Prevents execution of helper code when imported
• Useful for separating reusable code and test blocks
Code:
- dunder methods
What is it?
"Dunder" methods (like __str__, __len__, __eq__) are special functions with double underscores used to customize class behavior.
Where is it used?
In defining how objects behave with built-in functions (print(), len(), etc.)
How is it used?
Code:

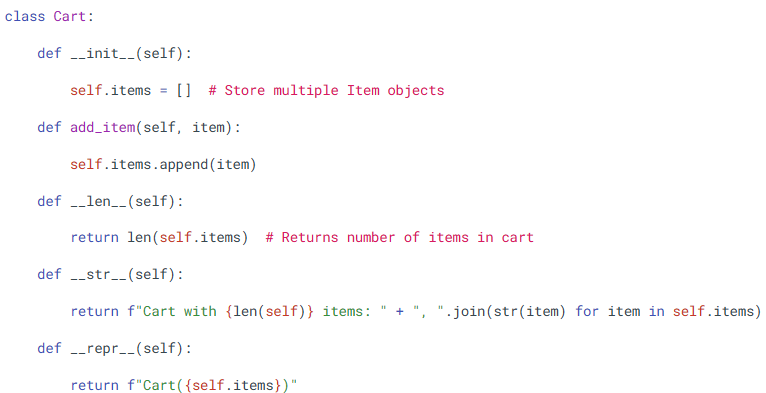
The Four Pillars of OOP
- Encapsulation,
What is it?
The practice of hiding internal object details and exposing only what's necessary.
Where is it used?
In protecting data integrity and restricting direct access to class attributes.
How is it used?
• Use _var for protected and __var for private variables
• Access data via getter/setter methods

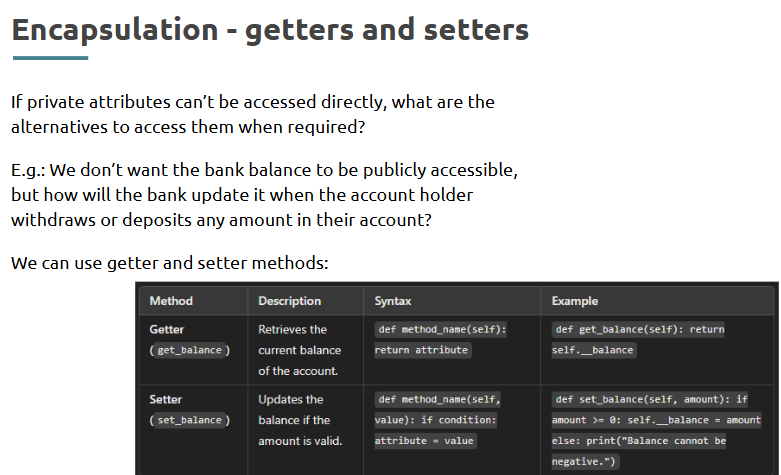
Code:
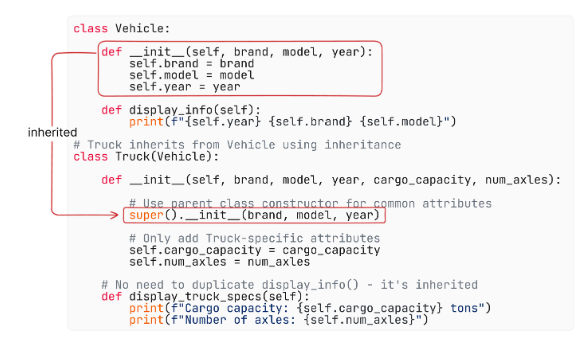
- Inheritance,
What is it?
One class (child) inherits attributes and methods from another (parent).
Where is it used?
In reusing code, like when LineChart inherits from a generic Chart class.
How is it used?
• Define parent class
• Use child class with super() for extending behavior
super():
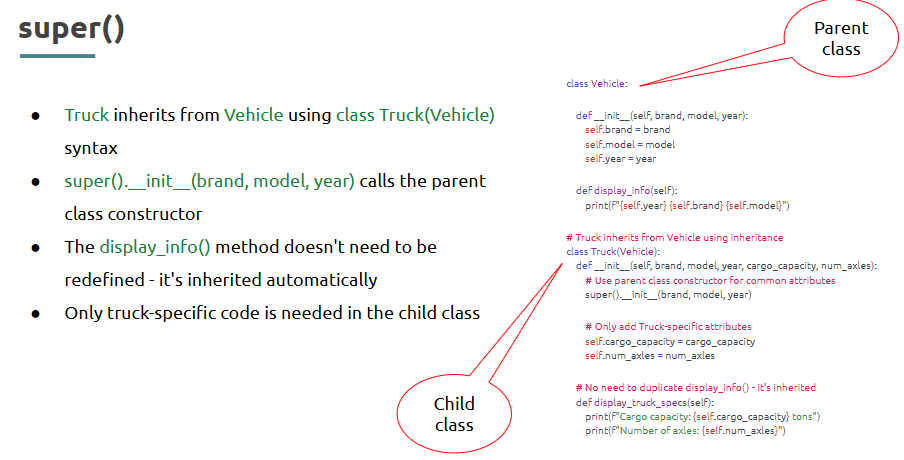
Code:
- Polymorphism,
Example:
Think of a UPI app (like Google Pay or PhonePe):
The user enters the UPI ID and amount, then clicks "Pay".
The system does not check which bank the user is using—each bank knows how to process the payment.
This is polymorphism—different banks implement pay() differently, but the app treats all banks the same.

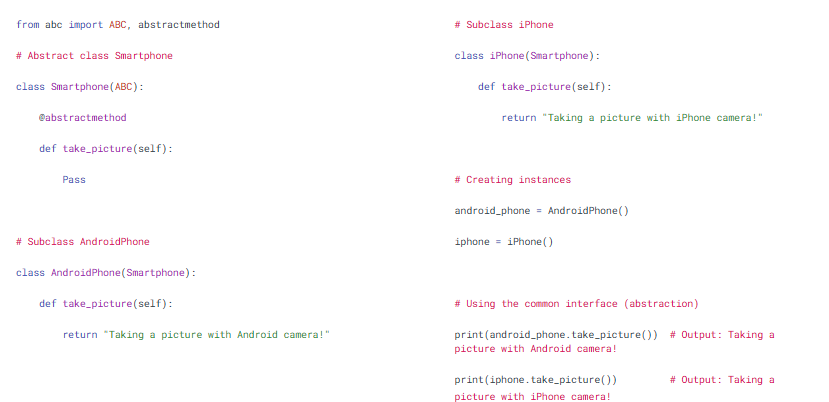
- Abstraction
Where is it used?
In user-defined libraries, dashboards, or ML pipelines to simplify usage.
How is it used?
In Python, we use:
Abstract classes
Abstract methods
to achieve abstraction.
An abstract class cannot be instantiated directly, and it forces the subclass to implement abstract methods.
Code:
Topic 10: Interview Readiness
- Most commonly asked coding questions
- NumPy and Pandas preparation
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article